AI 推断加速
- 最低时延的 AI 推断
- 加速整体应用
- 匹配 AI 创新的速度

具有最低时延的 AI 推断

高吞吐量或低时延
使用大批量可实现吞吐量。您必须等到所有输入准备就绪后再进行处理,这不可避免地增加了延迟。
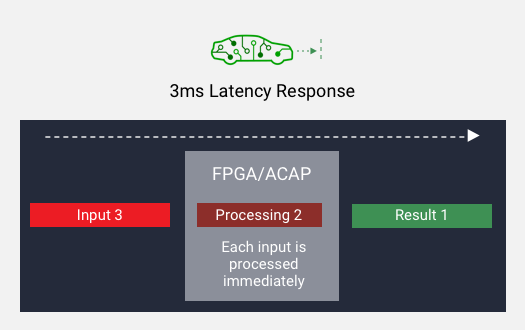
高吞吐量和低时延
使用小批量可实现吞吐量。在每个输入准备就绪后即可开始处理,从而降低了延迟。
加速整体应用
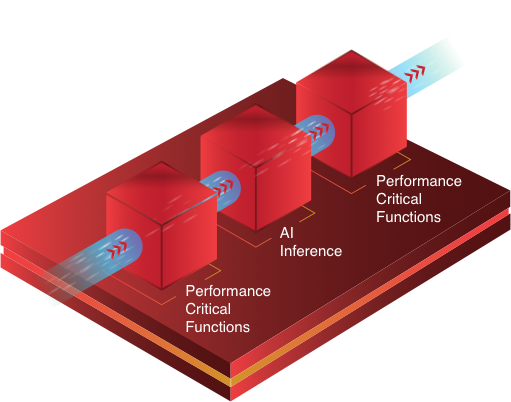
通过将自定义加速器与具有动态架构的芯片器件紧密耦合,可为 AI 推断和其他关键性能功能优化硬件加速。
与固定架构的 AI 加速器(例如 GPU)相比,它可显着提高整体应用性能。 而对于 GPU,应用的其他性能关键型功能必须在软件中执行,而不具备自定义硬件加速的性能和效率优势。

匹配 AI 创新的速度
人工智能模型正在迅速发展
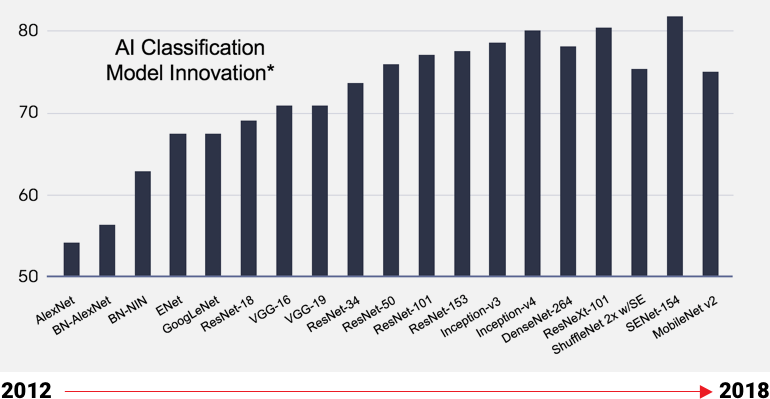
自适应芯片允许特定领域架构(DSA)更新,
无需新芯片,便可优化最新人工智能模型

固定硅器件的开发周期较长,因此尚未针对最新型号进行优化

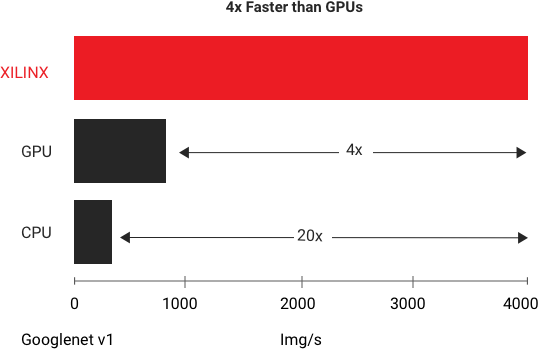
数据中心的 Vitis AI
AMD 能提供最高的吞吐量和最低的时延。在 GoogleNet V1 上运行的标准基准测试中,AMD Alveo U250 平台在实时推断中提供的吞吐量性能是最快 GPU 的四倍。 有关更多详细信息,请参见白皮书:使用 AMD Alveo 加速器卡加速 DNN(中文版)
边缘的 Vitis AI
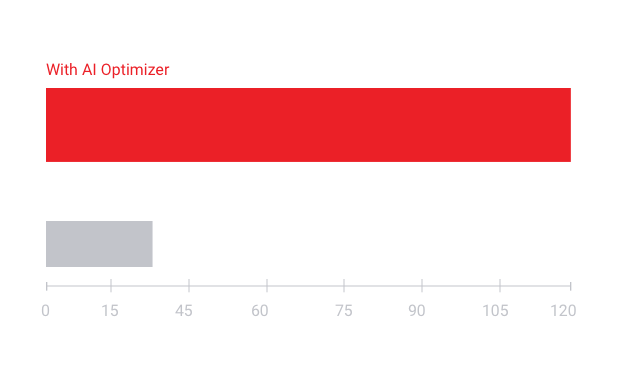
凭借 Vitis AI Optimizer 技术获得 AI 推断性能领先地位。
- 5 倍至 50 倍的网络性能优化
- 改善帧率(FPS),降低功耗
优化/加速编译器工具
- 支持 Tensorflow 和 Caffe 网络
- 将网络编译为优化的 AMD Vitis 运行时